Toonflow架构深度解析:从Agent设计到短剧创作全流程
最近花时间研究了 Toonflow 这个项目,一个开源的 AI 短剧工厂工具。它的核心想法挺简单——把小说文本变成短剧视频,全流程自动化。但真正深入研究后,我发现它的系统设计有很多值得学习的地方,特别是 Agent 的设计和模块之间的协作方式。
这篇文章从三个维度拆解 Toonflow:Agent 的定义架构、Agent 之间的协作机制、整个短剧创作的完整流程。三张架构图会穿插在文中,帮助理解设计思路。
一、为什么要用 Agent 模式
Toonflow 需要对接很多外部 AI 服务:大语言模型解析小说、图片生成模型画角色和分镜、视频生成模型生成视频片段。这些服务各自有不同的接口格式、调用方式、超时设置。
把这些调用逻辑散落在业务代码里,后期维护会很麻烦。换一个 AI 服务提供商要改动大量代码,不同服务的重试策略也难以统一。
Toonflow 采用了经典的代理模式,设计了一个 BaseAgent 抽象基类。所有具体的 Agent(LlmAgent、ImageAgent、VideoAgent)都继承自这个基类,统一实现核心方法。这种设计让 AI 调用的逻辑得到封装和复用。
二、Agent 定义架构:统一的抽象层
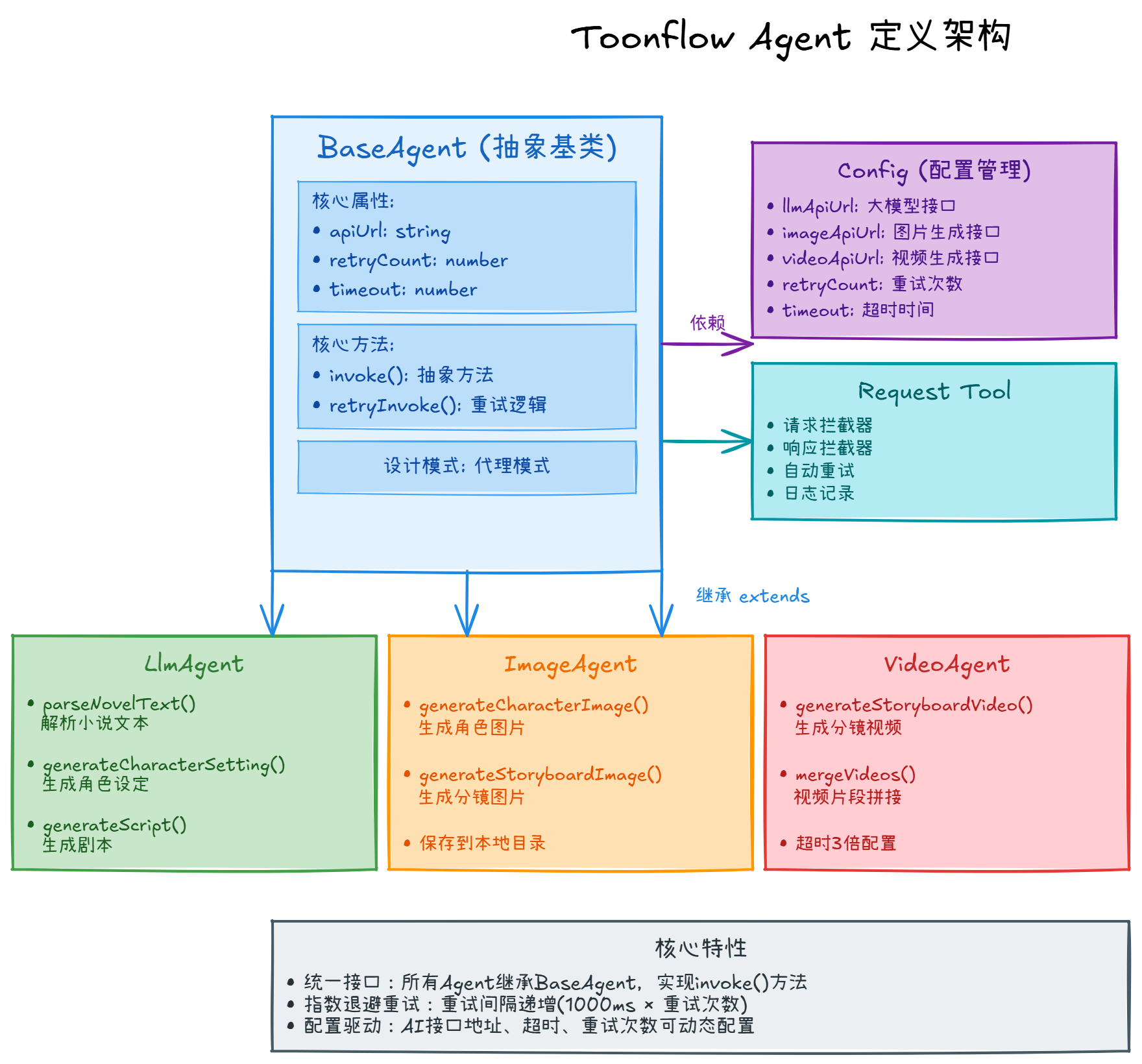
BaseAgent 抽象基类是整个 Agent 体系的核心。它封装了三个核心属性:apiUrl(AI 服务接口地址)、retryCount(重试次数)、timeout(超时时间)。这些属性从配置文件中读取,支持动态修改。用户在前端更换 AI 服务地址后,不需要重启后端。
最关键的是 retryInvoke 方法。它实现了指数退避的重试策略:第一次失败等待 1 秒,第二次等待 2 秒,第三次等待 3 秒。这种递增的等待时间在 AI 服务短暂不可用时能避免频繁重试,也给服务一定的恢复时间。
LlmAgent 负责对接大语言模型。它继承了 BaseAgent 的重试逻辑,只需要实现具体的调用细节。parseNovelText 方法会构造一个合适的 prompt,让 LLM 提取小说中的角色、剧情、场景信息。返回的结果会解析成 JSON 格式,方便后续处理。generateCharacterSetting 方法则根据提取出的角色基础信息,生成更详细的角色设定——包括外貌、性格、身份、服装风格,这些细节对后续的角色图片生成很关键。
ImageAgent 对接图片生成 AI 服务。它的 invoke 方法会将生成的图片保存到本地的 uploads 目录。生成角色图片存到 uploads/character,生成分镜图片存到 uploads/storyboard。前端通过静态资源路径访问图片。responseType 设置为 ‘arraybuffer’ 是必须的,因为图片接口返回的是二进制数据。
VideoAgent 的工作方式类似,但有个特殊点:视频生成耗时很长,所以超时时间设置成了普通 AI 调用的 3 倍。mergeVideos 方法拼接多个视频片段,生成完整的短剧视频。
三、Agent 协作机制:从服务编排到 AI 调用
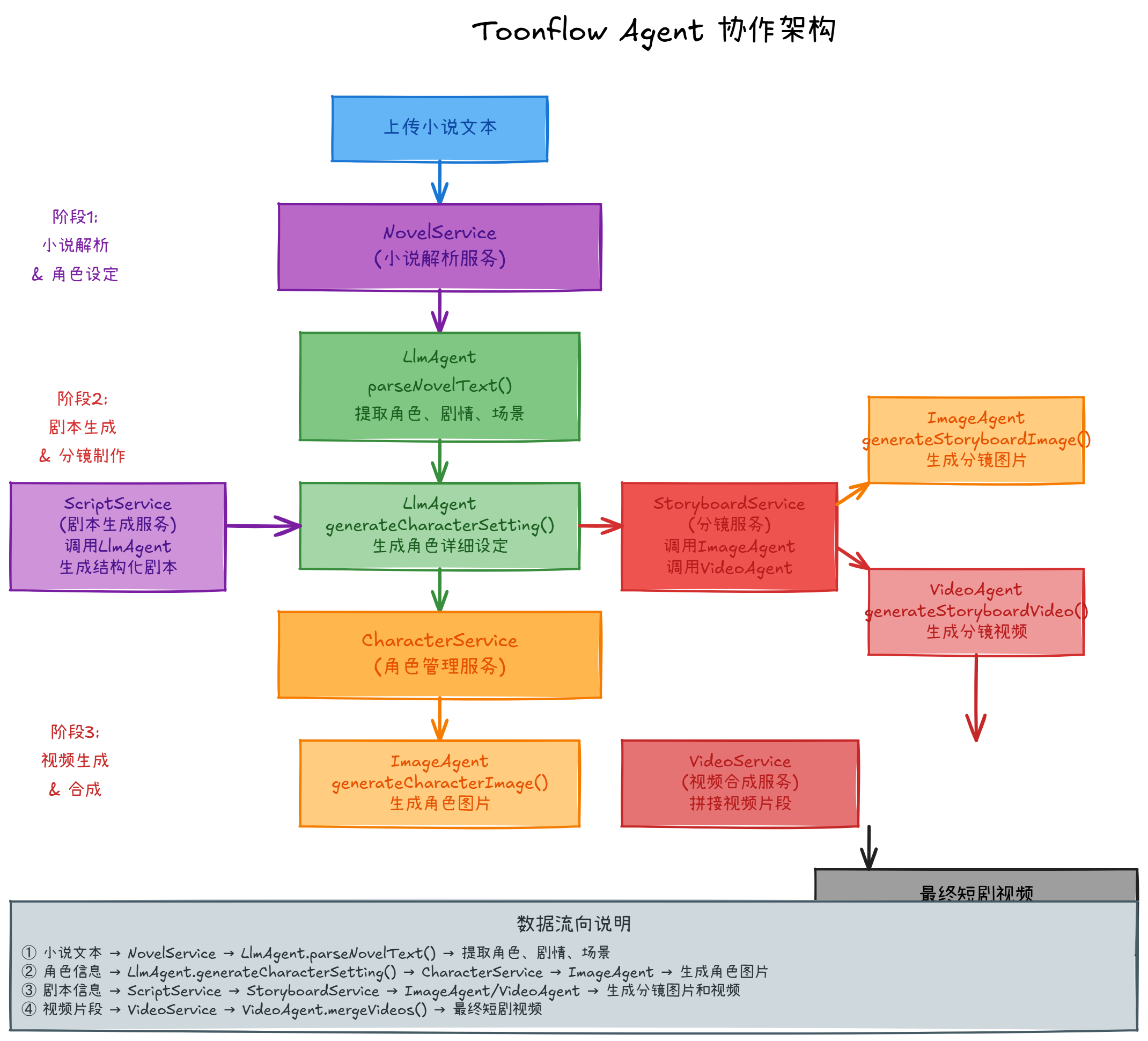
Toonflow 的业务逻辑层通过 Service 模块来组织,每个 Service 对应一个业务场景。Service 负责编排业务流程,Agent 负责实际的 AI 调用。这种分层让业务逻辑和 AI 能力分开。
小说上传后,NovelService 会调用 LlmAgent.parseNovelText() 解析小说文本。解析出的角色信息会交给 LlmAgent.generateCharacterSetting(),生成每个角色的详细设定。这个过程中,LLM 被调用了两次,但 Service 层不需要知道细节,只需传递数据、接收结果。
角色设定准备好后,CharacterService 会调用 ImageAgent.generateCharacterImage() 生成角色图片。生成的图片路径会更新到角色信息中,供剧本生成使用。
剧本生成时,ScriptService 把角色信息、剧情、场景组织成一个结构化的 prompt,调用 LlmAgent 生成剧本。剧本采用 JSON 格式返回,包含每个镜头的场景描述、角色对话、角色动作。
分镜制作由 StoryboardService 负责。它会调用 ImageAgent 生成分镜图片,调用 VideoAgent 生成分镜视频片段。这两个调用并行进行,因为图片和视频生成互不依赖,能提升效率。
最后,VideoService 调用 VideoAgent.mergeVideos() 把所有分镜视频按顺序拼接,生成最终的短剧视频。视频采用 1080x1920 的竖屏格式,适配移动端观看习惯。
数据从小说文本开始,经过多次 Agent 调用和 Service 处理,最终变成视频文件。每个 Agent 专注于自己的职责,Service 层负责协调,模块间的依赖关系清晰明确。
四、短剧创作全流程:从文本到视频
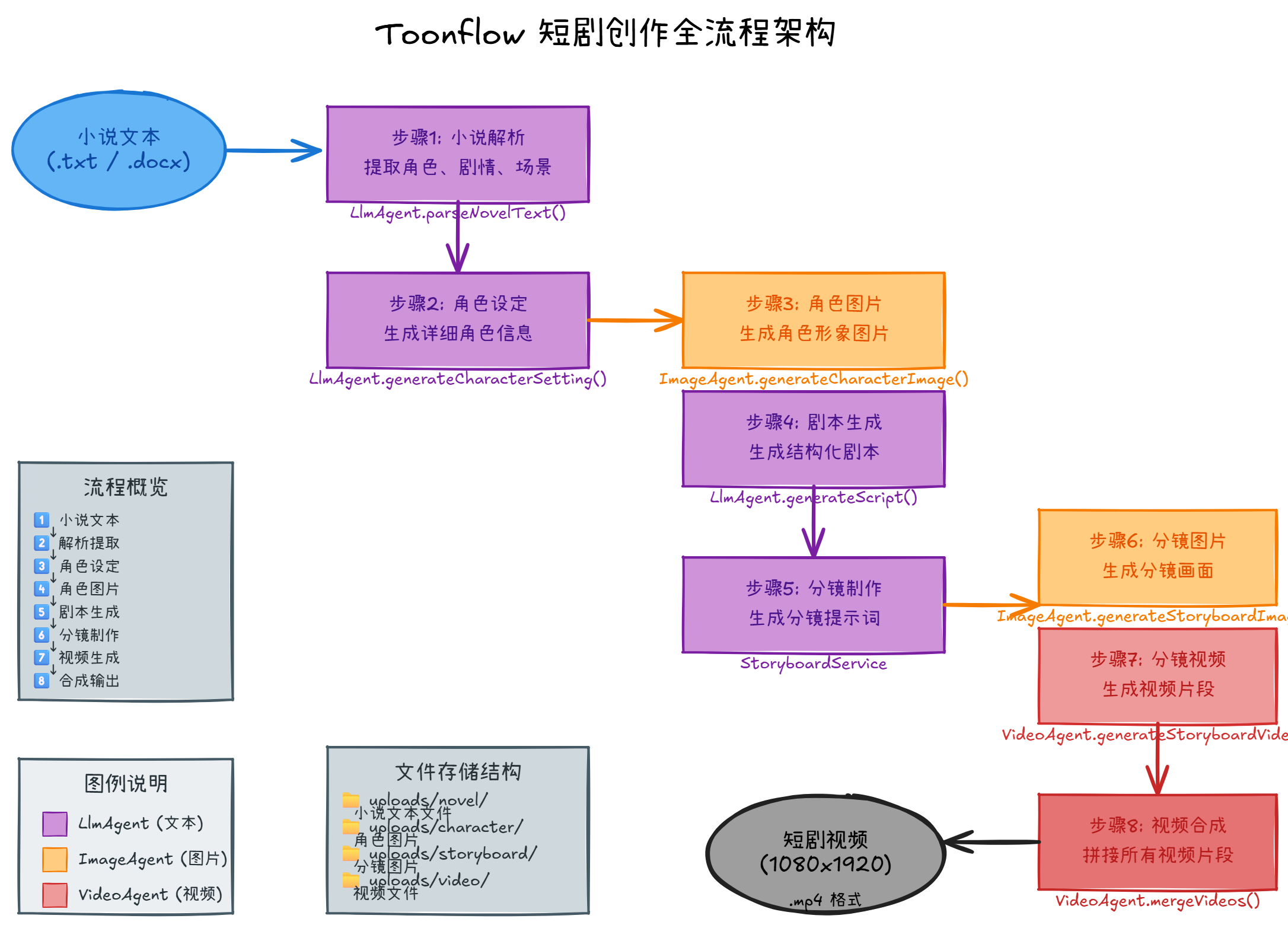
看完整个流程就能理解为什么 Toonflow 需要这么多模块。小说到视频的转换不是一步完成的,而是一个链式处理过程。
用户上传小说文本后,系统会先进行小说解析。这一步提取出了角色列表、核心剧情、场景设定。这是整个流程的基础,后续生成依赖这些信息。
角色设定生成是对提取出的角色信息的扩展。LLM 会根据角色的基础信息,生成详细的外貌描述、性格特点、身份背景、服装风格。这些描述让角色更丰满,也为角色图片的生成提供了视觉参考。
角色图片生成会调用专门的图片生成 AI。Toonflow 对角色图片的尺寸有特殊要求——800x1200 的比例,这样更适合竖屏短剧的展示。图片生成成功后会保存到本地,同时返回访问路径供前端展示。
剧本生成阶段会整合所有信息:角色的详细设定、核心剧情、场景描述。LLM 会基于这些信息生成结构化的影视剧本,包含每个镜头的场景描述、角色对话、动作指引。剧本采用 JSON 格式返回,方便程序解析。
分镜制作阶段把剧本拆解成具体的镜头。每个镜头对应一个视频片段,需要生成分镜图片和分镜视频。图片用于预览,视频用于最终拼接。这两个生成任务可以并行进行,提升效率。
视频片段生成完成后,最后一步是视频合成。多个视频片段按顺序拼接成完整的短剧,同时可以添加字幕、背景音乐等后期效果。最终视频保存为 MP4 格式,用户可以直接下载或分享。
整个流程下来,每个环节都有明确的输入输出,数据流转清晰。如果某个环节出现问题,可以快速定位是 Service 层的逻辑问题还是 Agent 层的调用问题。
五、技术亮点总结
研究完 Toonflow 的架构,我觉得几个设计值得借鉴。
分层解耦是第一个值得借鉴的设计。基础设施层、AI 能力集成层、核心业务逻辑层、接口适配层、前端交互层,每层职责明确,层与层通过标准接口通信。更换 AI 服务提供商变得很简单——只需修改 AI 能力集成层,业务逻辑层几乎不需要改动。
配置驱动是第二个值得借鉴的设计。AI 服务的接口地址、超时时间、重试次数都配置化了,支持动态更新。用户在前端修改配置后立即生效,不需要重启服务。
错误处理和重试机制是第三个值得借鉴的设计。BaseAgent 封装了统一的错误处理和重试逻辑,采用指数退避策略。这样既保证了调用的可靠性,又避免了对 AI 服务造成过大压力。所有调用记录详细日志,方便问题排查。
文件存储的规范管理是第四个值得借鉴的设计。uploads 目录按类型划分子目录:novel 存放小说文本,character 存放角色图片,storyboard 存放分镜图片,video 存放视频文件。结构化的存储让文件管理更清晰,也方便扩展新的文件类型。
六、一些思考
Toonflow 的设计并不复杂,但它把每个环节都处理得比较合理。好的架构不在于使用了多少复杂的设计模式,而在于能否清晰地解决问题。
Agent 模式在这里用得恰到好处。它既封装了 AI 调用的复杂性,又提供了统一的接口,让业务逻辑保持简洁。如果直接把 AI 调用散落在各个 Service 里,代码的可维护性会差很多。
流程也很重要。从小说到视频的转换不是单个 Agent 能完成的,需要多个 Agent 协同工作。Toonflow 通过 Service 层编排这些 Agent,让整个流程变得可控且易于调试。
当然,Toonflow 也有可以改进的地方。目前的视频拼接调用 AI 服务接口实现,实际上用 FFmpeg 在本地处理会更稳定。批量生成角色和分镜时,也可以引入并发控制,避免同时对 AI 服务造成过大压力。
总体来说,Toonflow 是一个很好的学习案例。它展示了如何在一个实际的 AI 应用中,通过合理的架构设计管理复杂性。如果你正在设计类似的 AI 应用,或者对 Agent 架构感兴趣,Toonflow 的源码值得深入研究。
参考资源:
- Toonflow 项目仓库:https://gitee.com/HBAI-Ltd/Toonflow-app
- 原始架构文档:https://www.jianshu.com/p/14c3012b6c8a




